Maximum Diversity Problem
Martí, Gallego and Duarte (2010)
Optsicom project, University of Valencia (Spain)
Problem Description
The maximum diversity problem (MDP) consists of selecting a subset of m elements from a set of n elements in such a way that the sum of the distances between the chosen elements is maximized. The definition of distance between elements is customized to specific applications. In most applications, it is assumed that each element can be represented by a set of attributes. Let sik be the state or value of the kth attribute of element i, where k = 1, ..., K. Then the distance between elements i and j may be defined as:
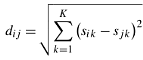
In this case, dij is simply the Euclidean distance between i and j. The distance values are then used to formulate the MDP as a quadratic binary problem, where variable xi takes the value 1 if element i is selected and 0 otherwise, i = 1, ..., n:
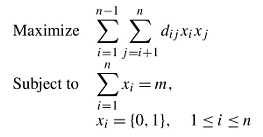
Kuo, Glover and Dhir (1993) use this formulation to show that the clique problem (which is known to be NP-complete) is reducible to the MDP.
State of the Art Methods
The most relevant approximated methods developed to solve this problem, categorized by methodology, are:
- GRASP based methdos
- GRASP_D2+I_LS: Constructive method coupled with a first-improvement local search. Duarte and Martí (2007).
- GRASP+PR: Hybrid method that combines GRASP methodology with Path-Relinking. Silva et al. (2007).
- Local search based methods
- ITS: Iterated Tabu Search that alternates tabu search with perturbation procedures. Palubeckis (2007).
- A_VNS: Variable neighborhood search method with a basic tabu search improvement method. Aringhieri and Cordone (2006).
- Population based methods
- G_SS: Scatter Search algorithm with memory structures. Gallego et al. (2009).
- MA: Memetic Algorithm that combines a population based approach with a local search approach. Katayama and Narihisa (2005).
Instances (MDPLIB)
We have compiled a comprehensive set of benchmark instances representative of the collections previously used for computational experiments in the MDP. We call this benchmark MDPLIB. Furthermore we have included new hard instances. A brief description of the origin and the characteristics of the set of instances follows:
- SOM: This data set consists of 70 matrices with random
numbers between 0 and 9 generated from an integer uniform distribution.
- SOM-a: These 50 instances were generated by Martí et al. (2010) with a generator developed by Silva et al. (2004). The instance sizes are such that for n = 25, m = 2 and 7; for n = 50, m = 5 and 15; for n = 100, m = 10 and 30; for n = 125, m = 12 and 37; and for n = 150, m = 15 and 45.
- SOM-b: These 20 instances were generated by Silva et al. (2004) and used in most of the previous papers (see for example Aringhieri et al. 2008). The instance sizes are such that for n = 100, m = 10, 20, 30 and 40; for n = 200, m = 20, 40, 60 and 80; for n = 300, m = 30, 60, 90 and 120; for n = 400, m = 40, 80, 120, and 160; and for n = 500, m = 50, 100, 150 and 200.
- GKD: This data set consists of 145 matrices for which
the values were calculated as the Euclidean distances from randomly
generated points with coordinates in the 0 to 10 range.
- GKD-a: Glover et al. (1998) introduced these 75 instances in which the number of coordinates for each point is generated randomly in the 2 to 21 range. The instance sizes are such that for n = 10, m = 2, 3, 4, 6 and 8; for n = 15, m = 3, 4, 6, 9 and 12; and for n = 30, m = 6, 9, 12, 18 and 24.
- GKD-b: Martí et al. (2010) generated these 50 matrices for which the number of coordinates for each point is generated randomly in the 2 to 21 range and the instance sizes are such that for n = 25, m = 2 and 7; for n = 50, m = 5 and 15; for n = 100, m = 10 and 30; for n = 125, m = 12 and 37; and for n = 150, m = 15 and 45.
- GKD-c: Duarte and Martí (2007) generated these 20 matrices with 10 coordinates for each point and n = 500 and m = 50.
- MDG-a: Duarte and Martí (2007) generated these 40 matrices, 20 of them with n = 500 and m = 50 and the other 20 with n = 2000 and m = 200. These instances were used in Palubeckis (2007).
- MDG-b: This data set consists of 40 matrices generated by Duarte and Martí (2007). 20 of them have n = 500 and m = 50, and the other 20 have n = 2000 and m = 200. These instances were used in Gallego et al. (2009) and Palubeckis (2007).
- MDG-c: This is a new data set with 20 matrices with n = 3000 and m ∈ {300, 400, 500, 600}. These are the largest instances reported of the MDPLIB. They are similar to those used in Palubeckis (2007).
The MDPLIB contains 315 instances and the best known values for the largest ones (SOM-b, GKD-c, MDG-a, MDG-b and MDG-c). They have been obtained by running G_SS and ITS for 2 hours of CPU time (in each instance) in a workstation Intel Core 2 Quad CPU Q 8300 with 6 GiB of RAM and Ubuntu 9.04 64 bits OS.
Computational Experience
We have performed a computational comparison of the state of the art methods on several of these the instances. We have considered a time limit in our comparative of 10 minutes per instance. In this experiment we compute for each instance and each method the relative deviation Dev (in percent) between the best solution value, Value, obtained with the method and the best known value of this instance, BestValue. For each method, we also report the number of instances #Best for which the method obtains the best value.
The experiment was performed in a Intel Core 2 Quad CPU Q 8300 with 6 GiB of RAM and Ubuntu 9.04 64 bits OS.
|
SOM-b |
MDG-a |
MDG-b |
MDG-c |
Summary |
|
|
GRASP_D2+I_LS |
|
|
|
|
|
|
Dev (%) |
0.02 |
0.51 |
0.53 |
1.62 |
0.62 |
|
#Best |
11 |
10 |
11 |
0 |
32 |
|
GRASP+PR |
|
|
|
|
|
|
Dev (%) |
0.02 |
0.50 |
0.45 |
3.18 |
0.85 |
|
#Best |
11 |
1 |
5 |
0 |
17 |
|
ITS |
|
|
|
|
|
|
Dev (%) |
0.00 |
0.01 |
0.01 |
0.04 |
0.02 |
|
#Best |
19 |
21 |
22 |
0 |
62 |
|
A_VNS |
|
|
|
|
|
|
Dev (%) |
0.00 |
0.04 |
0.06 |
0.08 |
0.05 |
|
#Best |
20 |
20 |
20 |
0 |
60 |
|
G_SS |
|
|
|
|
|
|
Dev (%) |
0.00 |
0.12 |
0.12 |
0.25 |
0.12 |
|
#Best |
20 |
20 |
19 |
0 |
59 |
|
MA |
|
|
|
|
|
|
Dev (%) |
0.00 |
0.11 |
0.12 |
0.16 |
0.10 |
|
#Best |
20 |
20 |
20 |
0 |
60 |
References
- R. Aringhieri, R. Cordone, and Y. Melzani. Tabu search vs. grasp for the maximum diversity problem. 4OR: A Quarterly Journal of Operations Research, 6(1):45–60, 2008.
- R. Aringhieri and R. Cordone. Better and faster solutions for the maximum diversity problem. Technical report, Universit degli Studi di Milano, Polo Didattico e di Ricerca di Crema, 2006.
- A. Duarte and R. Martí. Tabu search and grasp for the maximum diversity problem. European Journal of Operational Research, 178:71–84, 2007.
- M. Gallego, A. Duarte, M. Laguna, and R. Martí. Hybrid heuristics for the maximum diversity problem. Computational Optimization and Applications, 44(3):411, 2009.
- F. Glover, C.C. Kuo and K.S. Dhir. Heuristic algorithms for the maximum diversity problem. Journal of Information and Optimization Sciences, 19(1):109–132, 1998.
- K. Katayama and H. Narihisa. An evolutionary approach for the maximum diversity problem. In W. Hart, N. Krasnogor, and J.E. Smith, editors, Recent advances in memetic algorithms, volume 166, pages 31–47. Springer, Berlin, 2005.
- C.C. Kuo, F. Glover, and K. S. Dhir. Analyzing and Modeling the Maximum Diversity Problem by Zero-One programming. Decision Sciences, 24(6):1171–1185, 1993.
- R. Martí, M. Gallego, and A. Duarte. A branch and bound algorithm for the maximum diversity problem. European Journal of Operational Research, 200(1):36–44, 2010.
- G. Palubeckis. Iterated tabu search for the maximum diversity problem. Applied Mathematics and Computation, 189:371383, 2007.
- G.C. Silva, L.S. Ochi, and S.L. Martins. Experimental Comparison of Greedy Randomized Adaptive Search Procedures for the Maximum Diversity Problem. In Experimental and Efficient Algorithms, volume 3059 of Lecture Notes in Computer Science, pages 498–512. Springer Berlin / Heidelberg, 2004.
- G.C. Silva, M.R.Q. Andrade, L.S. Ochi, S.L. Martins, and A. Plastino. New heuristics for the maximum diversity problem. Journal of Heuristics, 13(4):315–336, 2007.